Airflow powers AI
背景介绍⌗
最近接手了一个项目,经过需求调研决定尝试使用 Airflow 调度数据生产,过程涉及:
- 从大数据 Hive 数据库整合数据宽表;
- 在 Spark 上运行 IRT 算法模型汇总 ADS 表。
从中学习了很多关于大数据的知识,同时也积累了如何通过 Airflow 提交 Spark 任务的经验,应当抽时间总结一下。
冰山之下⌗
如「冰山理论」所描述,我们所做的只是冰山露在水面的一角,隐藏在冰山之下更大的一部份是:
- Airflow + Celery
- Docker
- Hadoop(Hive) 集群
- YARN 集群(Spark over YARN)
接下来我们将关注在「冰山水面上的一角」来阐述我们如何利用这些已有的技术连结了整个系统。
Make DAG great again⌗
之前部门里有位算法大佬用 DAG(大佬念做「戴格」)实现了一套非常牛逼的文本和识别处理算法,然后每次讨论方案必谈 DAG, 所以 DAG 成了部门里都知道的一个梗,虽然大佬走了之后很少再有人提起 DAG,但是接下来我们会进行文艺复兴,让 DAG 再次出现在我们的日常技术讨论中。
Make DAG Great Again!
Airflow 介绍⌗
架构⌗
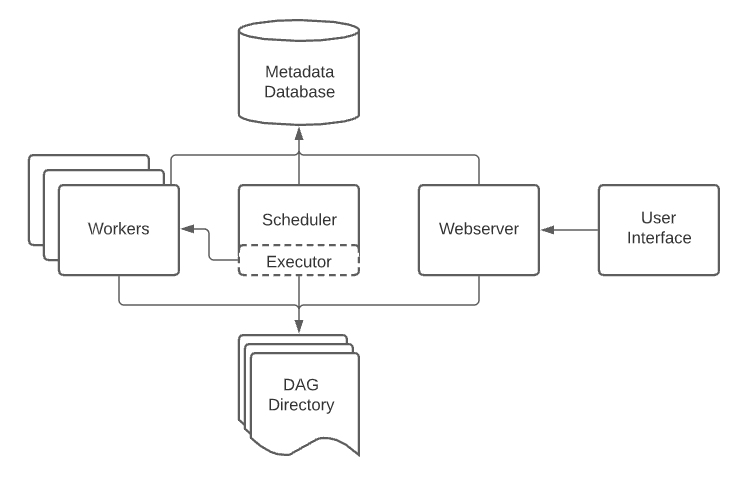
概念⌗
- DAG
- Operator
- Connection
Providers packages⌗
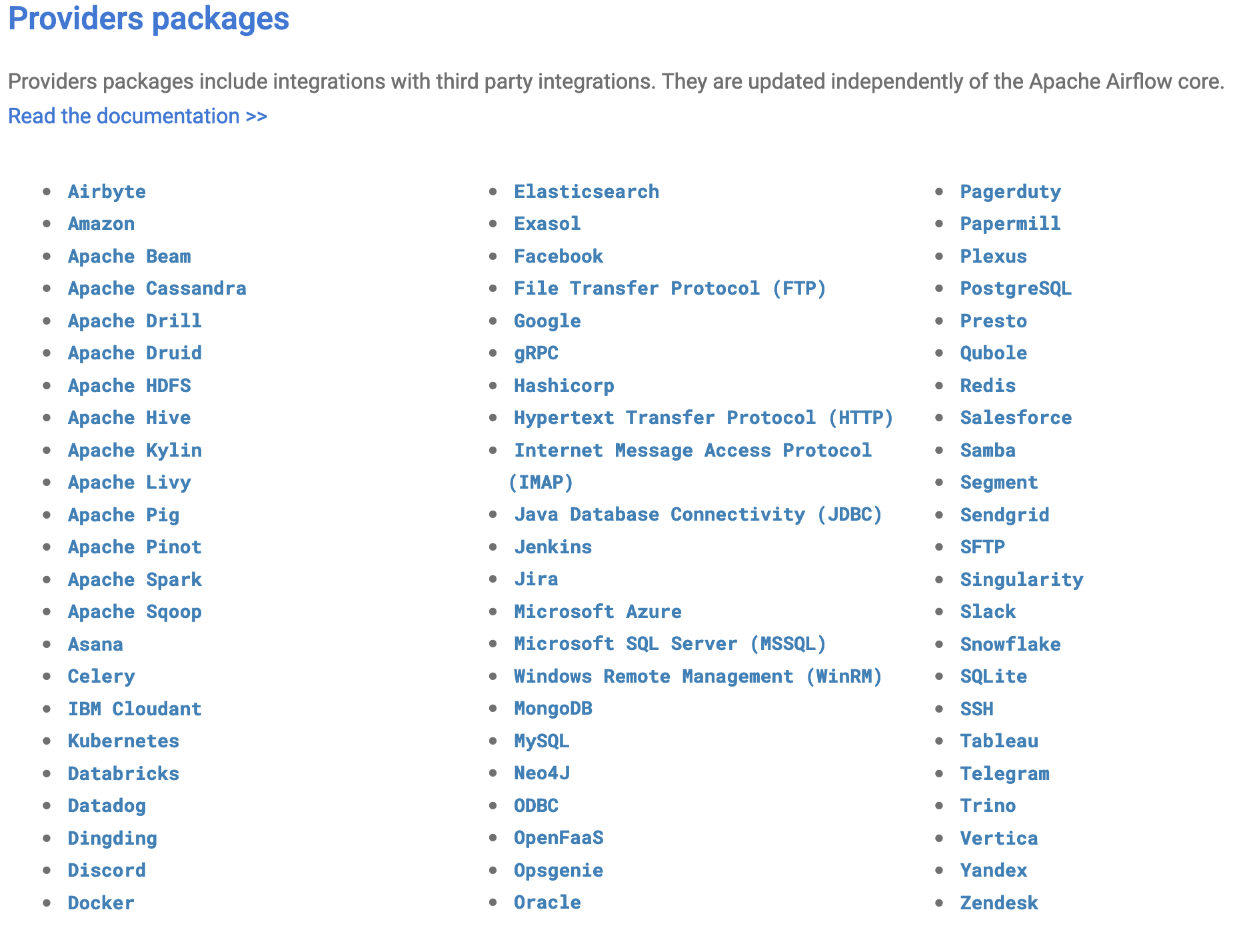 See also: Provider packages.
See also: Provider packages.
Spark 介绍⌗
架构⌗
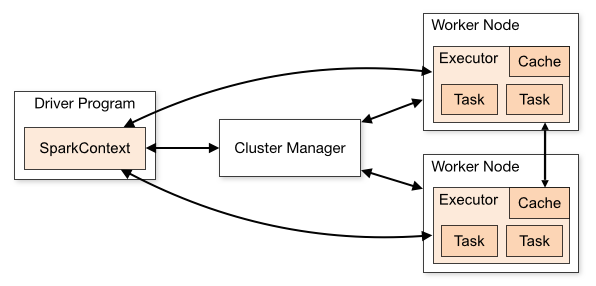
Spark 编程⌗
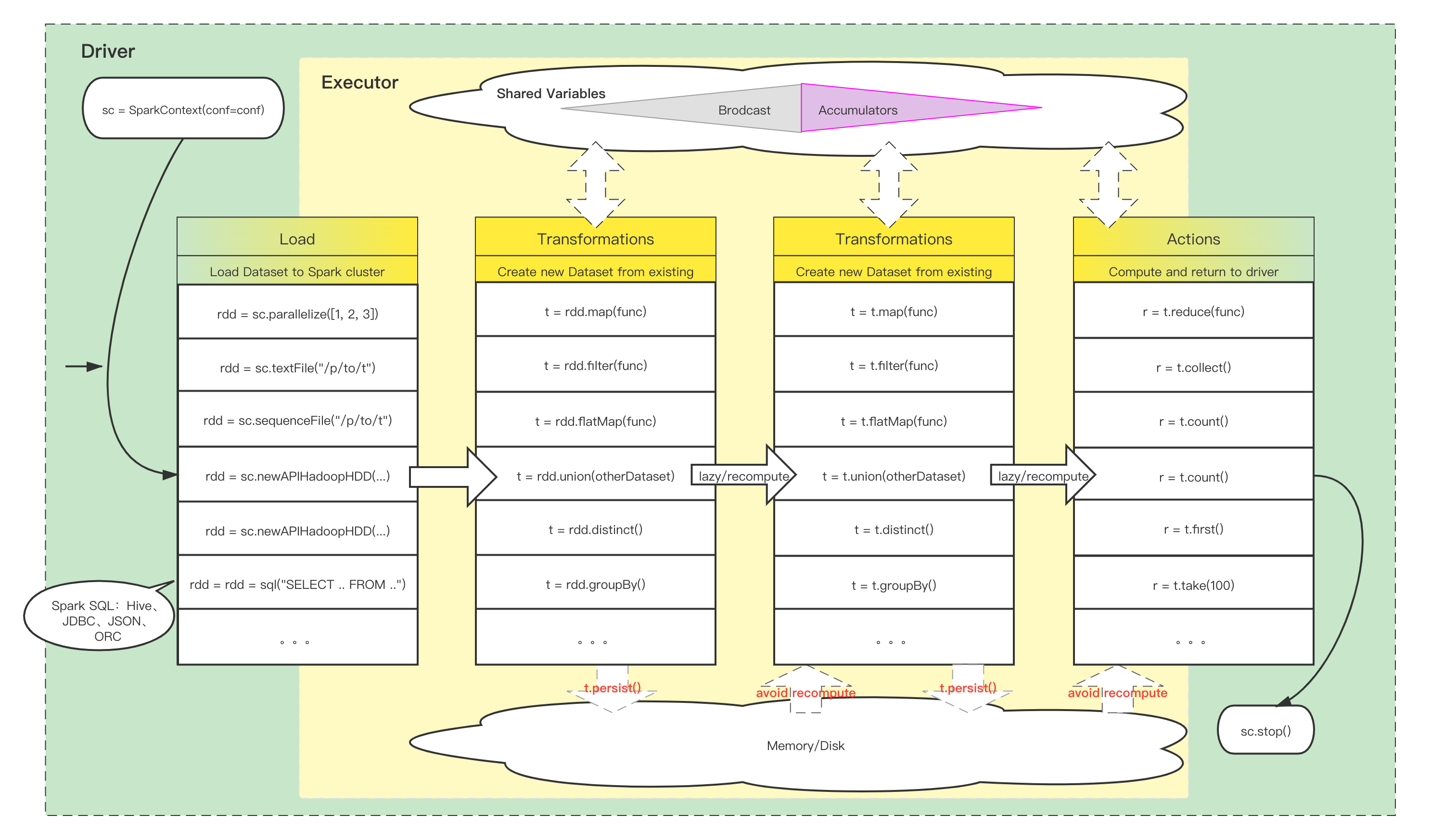
Spark SQL Hive Table 示例⌗
Airflow + Spark 平台化⌗
Celery Worker as a Spark Driver⌗
Celery Worker running on specific platform⌗
Windows⌗
Bigdata Hive client⌗
DAGs 分发⌗
提交 DAG⌗
Python 依赖解决⌗
- Spark
- Airflow
外部依赖?⌗
未来⌗
- 承接更多的报告需求
- 对内承接分析任务
- 可编程、平台化的分析